核心问题
传统 GPU 集群中,每个 GPU 只能访问本地显存(通常 80GB HBM),跨 GPU 内存访问需要通过 NVLink 或 PCIe,延迟高且带宽受限。如何构建机架级共享内存池,让所有 GPU 都能高效访问大容量内存?
FAM 架构总览
Fabric Attached Memory (FAM) 提出一种机架级内存架构,通过 NVSwitch Fabric 将多个 GPU 的内存池化,形成统一的超大内存空间。核心创新包括地址 Swizzling、Spraying 和 Compaction 三项技术。
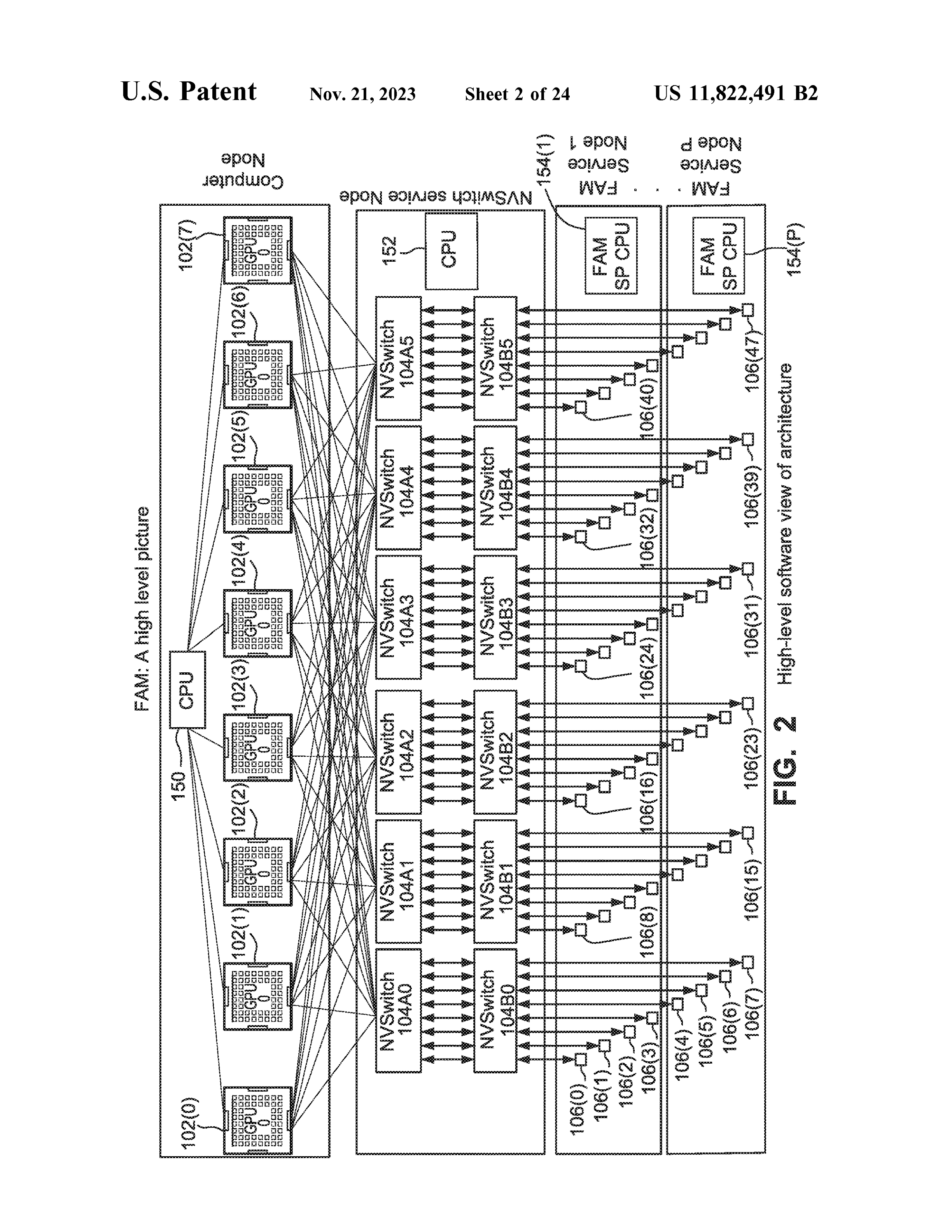
图 1: FAM 架构总览 (专利原图 FIG.2) — 左侧为 CPU + NVSwitch Fabric,中间为 Donor GPU 节点,右侧为 FAM 内存节点,通过 NVSwitch 互联
图 2: FAM 三级地址转换流程 — VA → Swizzled → Physical,通过 FAM Controller 统一管理
Address Swizzling
通过 XOR 哈希将连续虚拟地址分散到不同内存 Bank,避免 Bank 冲突,提升并行访问带宽。
Address Spraying
将地址空间均匀分布到多个 FAM 节点,实现负载均衡,避免热点节点成为瓶颈。
Address Compaction
对于未使用的地址区域进行压缩,减少地址映射表大小,提高 TLB 缓存效率。
问题
当多个 GPU 同时访问 FAM 内存时,如果地址映射是线性的,连续地址会映射到同一内存 Bank,导致 Bank 冲突和串行化访问,严重降低带宽。
地址 Swizzling 技术
Address Swizzling 通过 XOR 哈希函数将虚拟地址的某些位进行异或运算,使得逻辑上连续的地址在物理上映射到不同的内存 Bank 和 Channel,从而将串行访问转化为并行访问。
图 3: Address Swizzling 效果对比 — XOR 哈希将连续地址分散到不同 Bank,消除冲突
// 假设 4 Bank, 地址位 [2:0] 选择 Bank bank_select = (addr[2] XOR addr[5]) | (addr[1] XOR addr[4]) << 1; // VA[0] = 0x0000 -> Bank 0 // VA[1] = 0x0004 -> Bank 1 (而非 Bank 0) // VA[2] = 0x0008 -> Bank 2 (而非 Bank 0) // VA[3] = 0x000C -> Bank 3 (而非 Bank 0) 效果: 连续地址访问从串行 (25% 带宽) 提升到并行 (100% 带宽)
问题
FAM 系统包含多个内存节点(如 8 个 FAM Node,每节点 512GB),如果地址映射不均,某些节点会成为热点,而其他节点利用率低。
地址 Spraying 技术
Address Spraying 将地址空间均匀"喷洒"到所有 FAM 节点上,使得连续地址块分布在不同节点,实现负载均衡。类似于 RAID-0 的条带化,但粒度更细。
图 4: Address Spraying — 地址空间按条带分布到 4 个 FAM Node,实现负载均衡
node_select = (addr / stripe_size) % num_nodes; offset_in_node = (addr / stripe_size) / num_nodes * stripe_size + (addr % stripe_size); 示例: stripe_size=256, num_nodes=4 VA[0x0000] -> Node 0, offset 0x0000 VA[0x0100] -> Node 1, offset 0x0000 VA[0x0200] -> Node 2, offset 0x0000 VA[0x0300] -> Node 3, offset 0x0000 VA[0x0400] -> Node 0, offset 0x0100
问题
FAM 地址空间可能非常大(如 4TB),但实际使用的地址可能是稀疏的。完整的地址映射表会占用大量内存,且 TLB 缓存效率低下。
地址 Compaction 技术
Address Compaction 将稀疏使用的地址区域压缩为连续块,减少地址映射表的条目数量。未使用的地址区域被"折叠"掉,只保留实际使用的地址映射。
图 5: Address Compaction — 移除未使用的地址空洞,将稀疏地址空间压缩为连续块
原始地址空间: 64KB (65536 地址) 实际使用: Region A (4KB) + Region C (4KB) = 8KB 空洞: Region B (28KB) + Region D (28KB) = 56KB 压缩后地址空间: 8KB (8192 地址) 地址映射表大小: 64KB → 8KB (减少 87.5%) TLB 命中率提升: 3x+
FAM 硬件实现
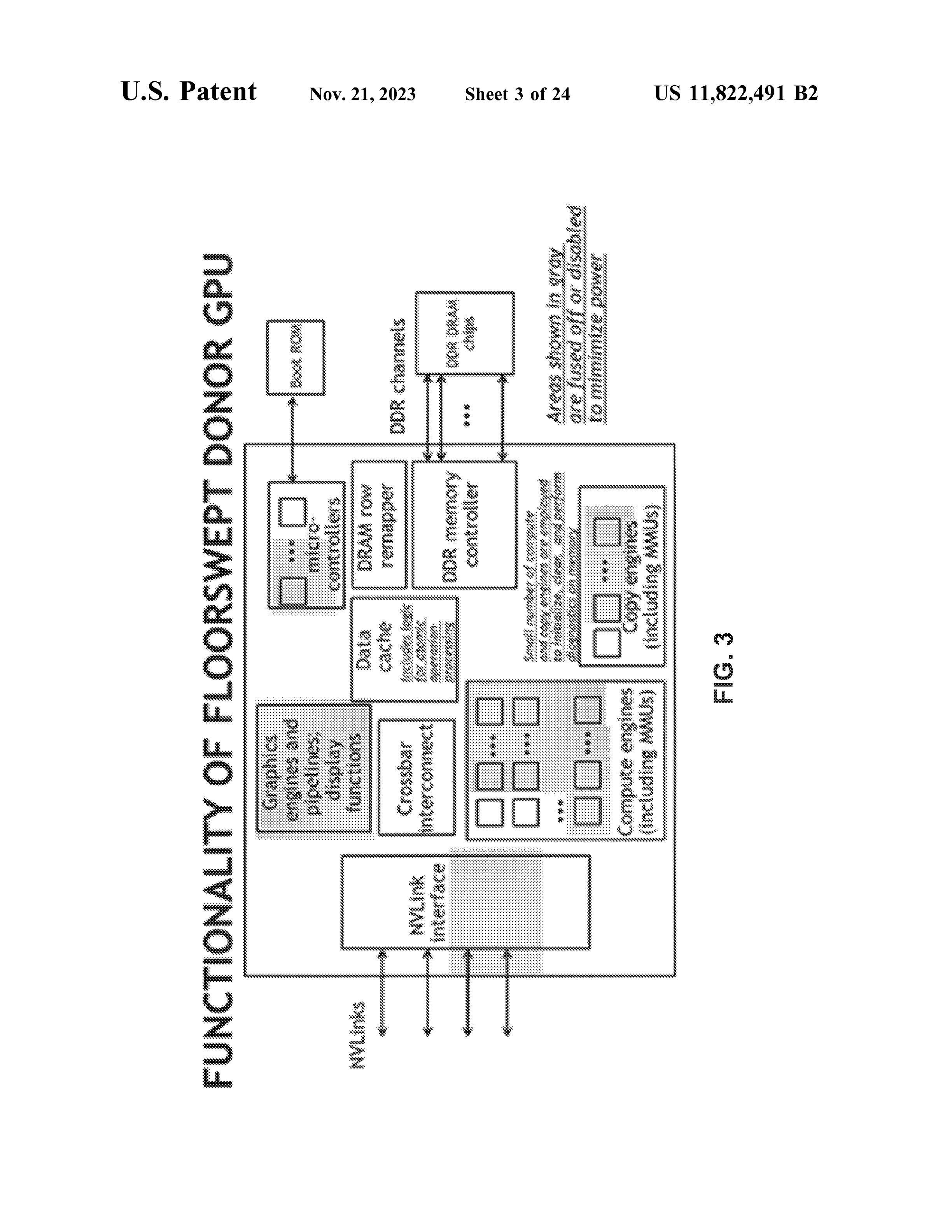
图 6: Donor GPU 功能框图 (专利原图 FIG.3) — 展示 NVLink Interface、RDMA Row Controllers、DDR Controllers、Crossbar Switch 等组件
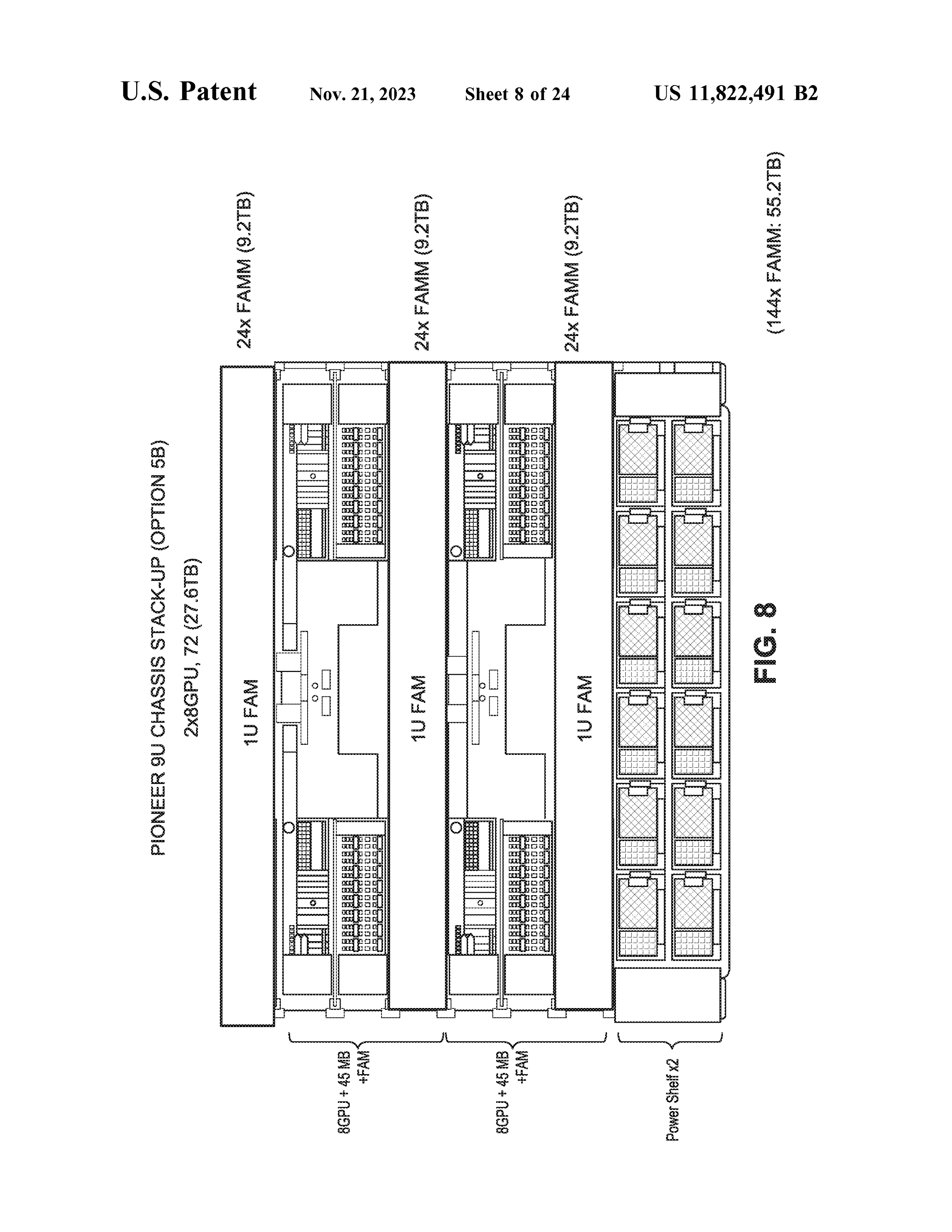
图 7: 机架级 FAM 堆叠架构 (专利原图 FIG.8) — 展示 Pioneer R/U Chassis 中 8GPU + FAM 的物理布局,支持 72 或 218TB 配置
关键硬件组件
NVSwitch Fabric
提供 GPU 与 FAM 之间的高速互联,支持 900GB/s 双向带宽
FAM Controller
每个 FAM Node 包含独立的控制器,处理地址转换、请求路由和数据搬运
DDR5 Memory
FAM 使用标准 DDR5 内存条,每 Node 配置 32 条,提供大容量低成本存储
RDMA Engine
支持远程直接内存访问,GPU 可直接读写 FAM 内存,无需 CPU 参与
Floor-Swept GPU
利用有缺陷的 GPU 芯片作为 Donor,降低成本,FAM 架构天然适合这种设计
8 GPU + 4 FAM Nodes 每 FAM Node: 32x DDR5 16GB = 512GB 总 FAM 容量: 4 × 512GB = 2TB 扩展配置 (Chassis Stackup): 8GPU + 1U FAM: 512GB 8GPU + 2U FAM: 2TB 72 GPU 配置: 218TB FAM (选项 B)
FAM vs CXL 对比分析
| 特性 | FAM (NVIDIA) | CXL 4.0 |
|---|---|---|
| 互联协议 | NVLink/NVSwitch | CXL/PCIe |
| 带宽 | 900 GB/s (NVLink 5.0) | 128 GB/s (PCIe 6.0 x16) |
| 延迟 | ~300ns (GPU 到 FAM) | ~500ns (CPU 到 CXL 内存) |
| 内存类型 | DDR5 (低成本) | DDR5 / HBM |
| 最大容量 | 218TB (72 GPU 配置) | 64TB (单主机) |
| 地址转换 | Swizzling + Spraying + Compaction | 标准页表 |
| 一致性 | 硬件维护 (NVLink) | CXL.cache 协议 |
| 主要场景 | GPU 显存扩展、AI 训练 | CPU 内存扩展、通用计算 |
| 生态成熟度 | NVIDIA 专有生态 | 开放标准 (Intel 主导) |
总结
FAM 是 NVIDIA 针对 GPU 集群优化的机架级内存架构,通过 NVSwitch Fabric 实现高带宽低延迟的 GPU-内存互联。相比 CXL 4.0,FAM 提供更高的带宽和更大的容量,但绑定 NVIDIA 生态。三项地址转换技术 (Swizzling/Spraying/Compaction) 是 FAM 性能优势的核心。